Money Talks: Predicting Fantasy Performance Using Player Contract Data (Fantasy Football)
Player contracts tell us almost everything a team feels about them – NFL contract data carries implicit information about a player’s expected role, team investment, and organizational confidence that complements raw performance statistics. A player on a high-value extension is more likely to maintain playing time than one in the final year of a cheap deal. A team that spends heavily at the QB or WR position signals a pass-heavy scheme, and these signals are not fully baked into conventional fantasy rankings.
I have built a machine learning model that takes in player contract data and uses it to predict their average fantasy points for the next season. In completing this model, the main question is: Can contract data help in predicting year-over-year player performance well enough to provide a meaningful edge?
Analysis
To read more about the methodology used to build this model, please refer to the ‘Methodology’ section near the bottom of the page.
To summarize, this model uses the following data to predict a player’s fantasy points per game for the next year:
- Fantasy points per game for the three previous seasons
- EPA and other performance metrics from the previous season
- $ AAV
- Total contract value
- Guaranteed contract value
- Contract duration
- Cap hit per year
- Years remaining on contract
- Year signed (contract)
- QB $ AAV
- OL $ AAV
- WR $ AAV
- Average $ AAV of teammates in the same position
- Age
In this, I looked to combine performance metrics with true contract data to capture the true value of each player, in turn highlighting their expected performance for the coming years.
To test the hypothesis, I trained three separate models: one using only t-relevant data, one using only player performance-relevant data, and one using both. The results are shown below for all three models, with CV R-squared being the cross-validation R-squared done during training.

Stats alone explain 43.6% of the variance in cross-validation. Adding contract data improves this to 47.3% – a meaningful but not transformative lift. However, the contract-only model still explains 41.2% of variance with zero knowledge of how the player actually played, validating the core hypothesis that team investment encodes real information about expected role. It makes sense that using stats and contract together doesn’t provide much uplift – after all, contract value is directly tied to performance, amongst a few other factors.
The following chart shows the top model’s predictions against actual 2024 fantasy data for all qualified players, broken down by position. Points above the diagonal (teal-colored) indicate players who outperformed the model’s prediction, and vice versa for the pink.
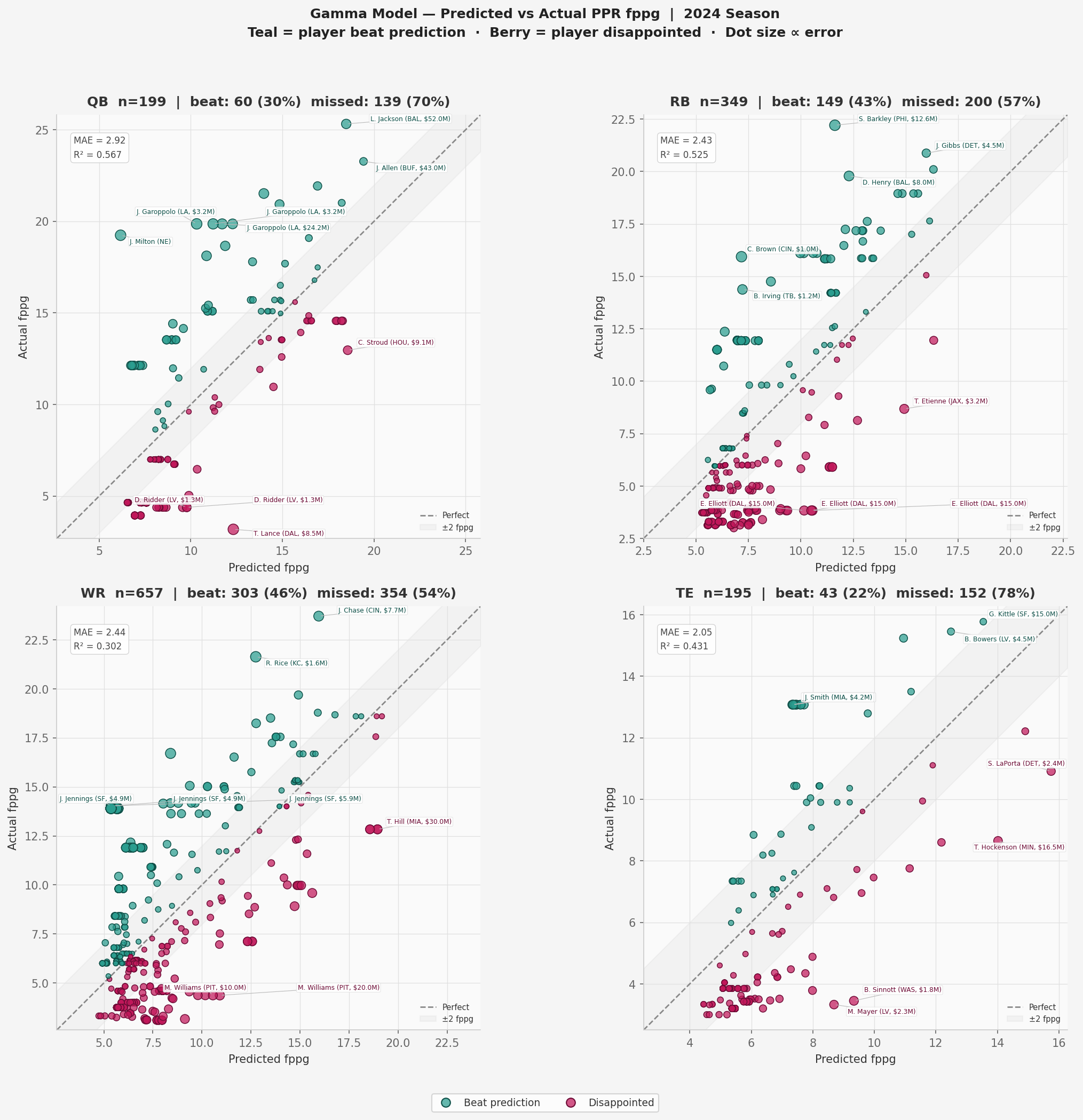
Key observations:
- QB: Pass throwers are highly predictable by contract value. The R-squared shows that about 57% of the variance in fantasy performance can be explained by the variance in contract data, which is a significant amount for real-world data.
- RB: Rushers are also highly predictable by contract value. Over 53% of variance is explained by the relationship; however, the 43% of players who outperformed prediction show the high upside of the position.
-
WR: Receivers are the most unpredictable position, with only 30% of variance explained by the relationship with the model parameters. This is also the highest upside group, with 46% of players outperforming expectations.
-
TE: The model is strongly optimistic about TEs – 78% disappointed. A common pattern exists, where the model predicts stability and TE output declines sharply.
Now that we know there is a moderate correlation between contract specifications and fantasy performance, can we predict the directionality of a player’s performance using the same parameters? That said, can we predict whether a player will stay the same, get better, or get worse?
I adapted the model to predict just that and achieved a 73.5% accuracy. Now, do not get too excited; this high accuracy number is a bit misleading. The following confusion matrix plots the results from a test from 2020 to 2024 with this model.
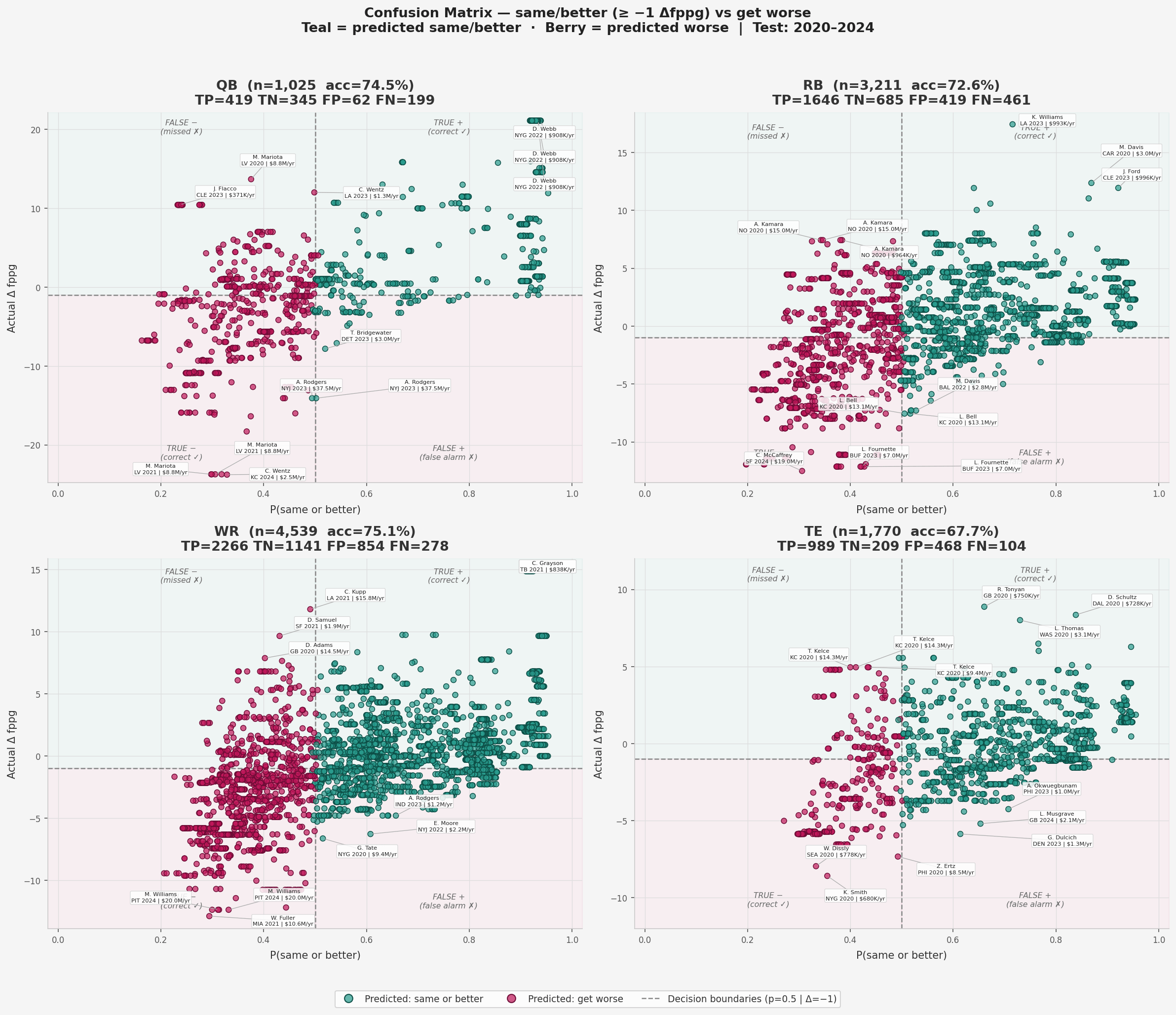
The model’s precision is strongest when calling “same or better” (80% of those calls are correct), while the recall for player declines is weak at ~57% – the model catches just over half of players who actually got worse, missing the other half by predicting stability. In practice, this means the model is most useful as a confidence filter for good picks rather than a bust detector: when it says a player is fine, trust it; when it says decline, treat it as one signal among many.
Looking into these results further, we can look at the accuracy by position for these predictions.
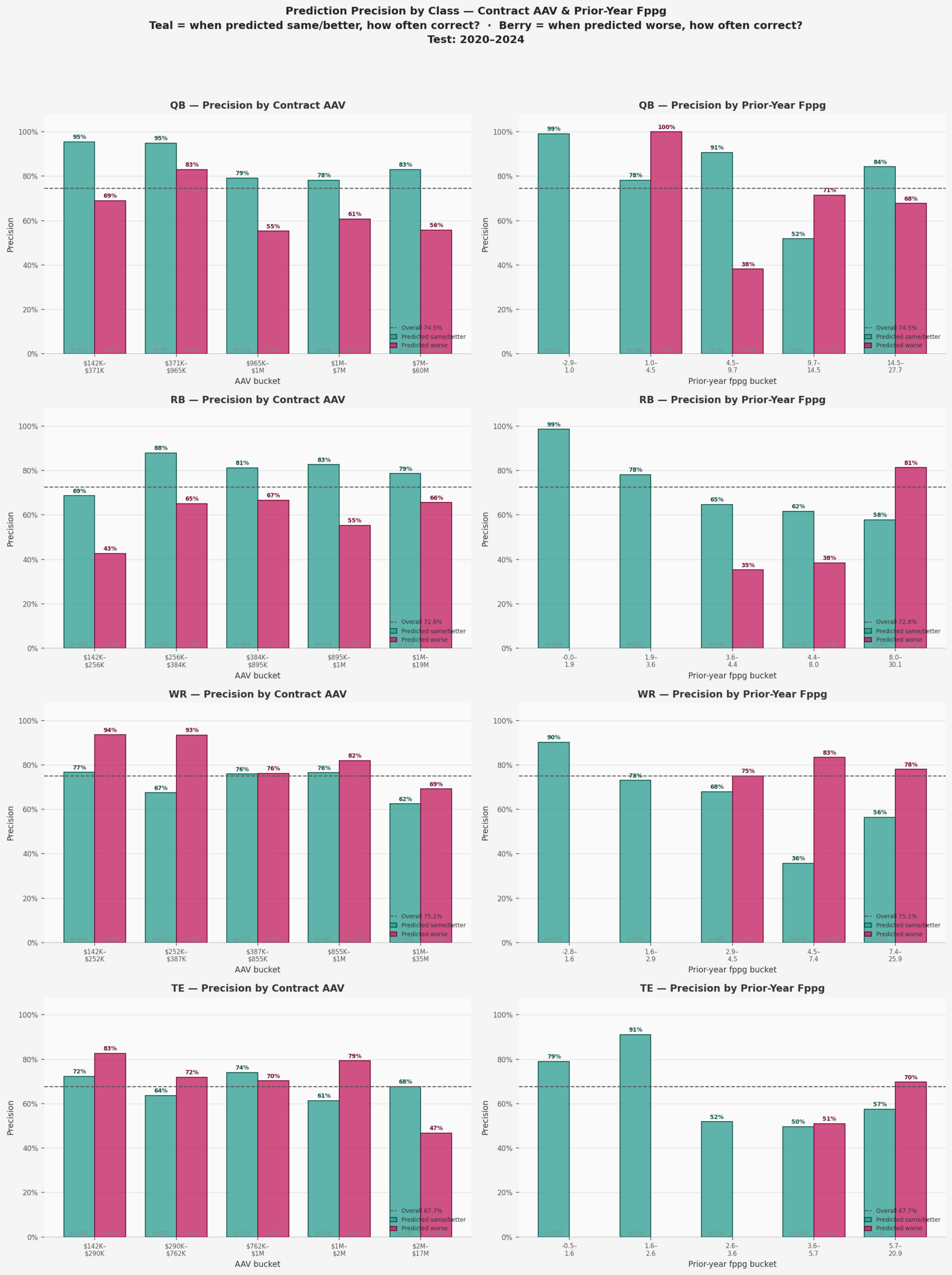
Notable findings:
- High-AAV QBs: The model is very confident predicting stability for elite-paid QBs (teal precision near 90%) – but ‘get worse’ calls for QBs are no better than chance.
- Mid-range RBs (2–5 fppg prior year): The model struggles most here. This is likely the committee-back zone where carries are unpredictably distributed.
- Top-earning WRs: Large contracts signal elite usage – teal precision spikes for the highest AAV WRs, confirming that big WR deals are a reliable stability signal.
- TE precision: The model rarely predicts TE decline (82% of TEs predicted ‘same/better’), so the berry bars have small sample sizes and are noisy.
Simply put, the model isn’t revealing much to us that we didn’t already know.
Conclusion
When it comes down to it, how correlated is money and a player’s contract to their fantasy performance? Well, very. However, correlation does not mean causation. While contract value is a great indicator of how valuable a player is and is a good check to see the opportunity or expectations you should have for a given player, it is not a reliable predictor of fantasy points. While money talks, contract details should be a single point of many when evaluating players – it can be very telling for players on their way out, as well as players who are going to stick around in an offensive system, but again, it can’t be the only consideration for performance.
Method
Data Sources
Weekly player statistics were pulled from nflverse (the R/Python NFL data ecosystem backed by nflfastR) for seasons 2010-2025. This covers all offensive skill positions: QB, RB, WR, and TE. The weekly data was aggregated to season level, computing total fantasy PPR points and points-per-game (fppg) as the primary performance metric. Contract data was sourced from NFLverse’s historical contracts dataset, which aggregates Over The Cap records. This provides per-contract information including total value, average annual value (AAV), guaranteed money, signing year, and contract length. The dataset covers roughly 51,000 contracts spanning 1990–2026, with reliable skill-position coverage from approximately 2011 onward.
Feature Engineering
The most powerful predictors are prior seasons of performance. I used one, two, and three-year lags for all key statistics:
- lag_fppg / lag2_fppg / lag3_fppg – points per game in each of the past three seasons
- Total PPR points, games played, rushing/receiving/passing yardage, and TDs
- EPA-based efficiency metrics (passing EPA, rushing EPA, receiving EPA)
- Target share and air yards share for receivers
For each player-season, I joined the active contract covering that year and computed contract state variables:
- aav / value / guaranteed – base financial scale of the deal
- contract_years / years_remaining – where the player is in their deal
- guaranteed_pct – proportion of deal protected
- year_signed – recency of contract (captures market evolution)
- Inflation-adjusted variants for cross-era comparisons
A novel addition: for each player-season, I compute the aggregate contract investment at other positions on their team – signals of offensive scheme and resource allocation:
- qb_aav – QB investment on team (proxy for passing game quality, for WR/TE)
- ol_aav_total – offensive line total cap (blocking quality proxy for RB)
- wr_aav_total / wr_count_above_5M – WR competition depth (target share signal)
- teammate_aav_mean/sum/count – same-position teammate investment
Age (computed from birth year), draft round, draft pick, and a changed_team boolean flag (players who switch teams typically regress to the mean in year 1). Rookie season is included as a proxy for experience and contract structure. Players averaging fewer than 3 PPR fppg in a season are excluded. This removes IR stints, pure backups, and garbage-time appearances that add unpredictable noise. The filter reduced the dataset from ~30,000 to ~17,800 qualified player-seasons – a meaningful cleaning that significantly improved model RÇ.
Model Development
I used XGBoost gradient-boosted trees throughout. Tree-based models are well-suited to this problem: the feature relationships are non-linear (e.g., contract value matters differently for QBs vs TEs), features are heterogeneous (dollar amounts, rates, counts, booleans), and missing data is common in the contract join – all handled natively by XGBoost without imputation.
Critically, I never used random train/test splits. A player’s future performance cannot inform their past. All validation uses a strict walk-forward scheme: train on years 1..T, validate on year T+1. Four CV folds were used (val years 2016–2019), with a hard holdout set for 2020–2024 that was never used during development.
Transformations
Predicting raw fppg is complicated by the right-skewed distribution of player output — a few elite players score 20+ fppg while most cluster between 4–12. We tested three target specifications:
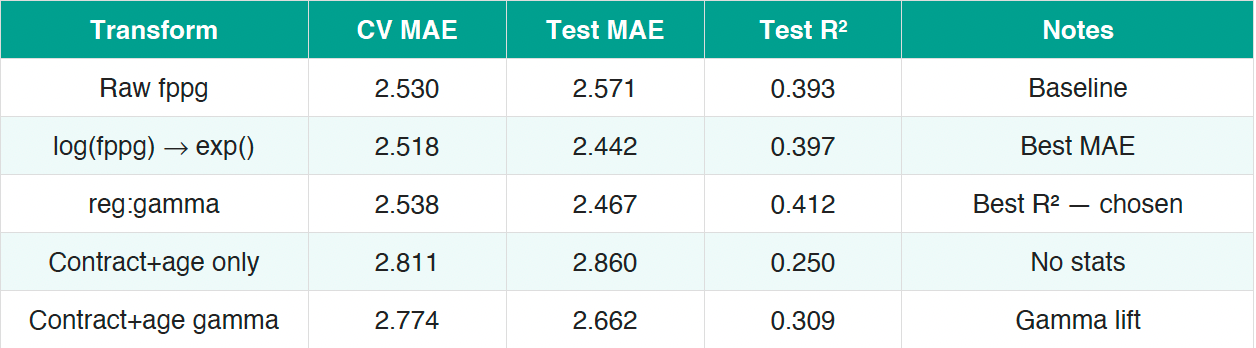
The gamma objective (reg:gamma) treats fppg as a positive, right-skewed continuous variable – mathematically equivalent to minimizing mean absolute percentage error on the log scale. It produced the highest R-squared (0.412) and was selected as the production model.
Comments
Please explain your acronyms for those of us that aren’t so deep in the weeds. No doubt your smarts and effort. End result is . . . . . not worth reading.